文章来源:
angula
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至2384272385@qq.com举报,一经查实,本站将立刻删除。

前言
只有光头才能变强
索引和锁在数据库中可以说是非常重要的知识点了,在面试中也会经常会被问到的。
本文力求简单讲清每个知识点,希望大家看完能有所收获
声明:如果没有说明具体的数据库和存储引擎,默认指的是MySQL中的InnoDB存储引擎
一、索引
在之前,我对索引有以下的认知:
看起来好像啥都知道,但面试让你说的时候可能就GG了:
1.1聊聊索引的基础知识
首先Mysql的基本存储结构是页(记录都存在页里边):
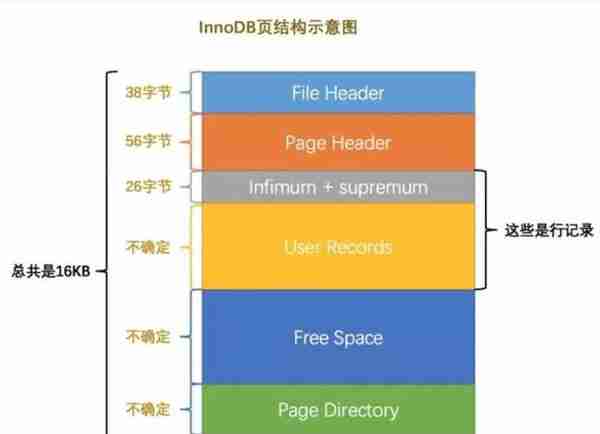
所以说,如果我们写select * from user where username = 'Java3y'这样没有进行任何优化的sql语句,默认会这样做:
很明显,在数据量很大的情况下这样查找会很慢!
1.2索引提高检索速度
索引做了些什么可以让我们查询加快速度呢?
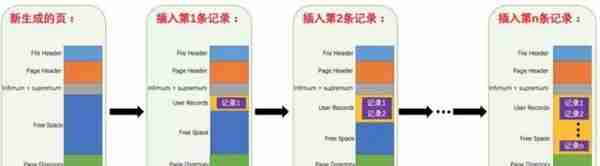
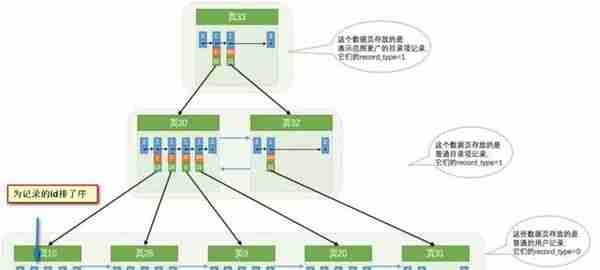
其实就是将无序的数据变成有序(相对):
要找到id为8的记录简要步骤:
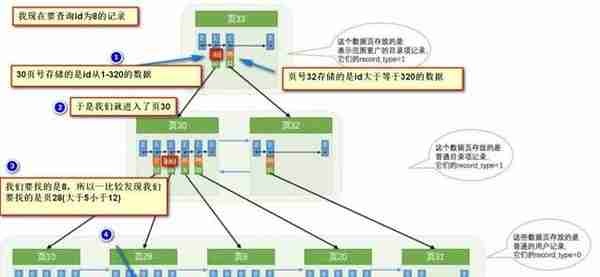
很明显的是:没有用索引我们是需要遍历双向链表来定位对应的页,现在通过**“目录”**就可以很快地定位到对应的页上了!
其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
参考资料:
1.3索引降低增删改的速度
B+树是平衡树的一种。
平衡树:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
如果一棵普通的树在极端的情况下,是能退化成链表的(树的优点就不复存在了)
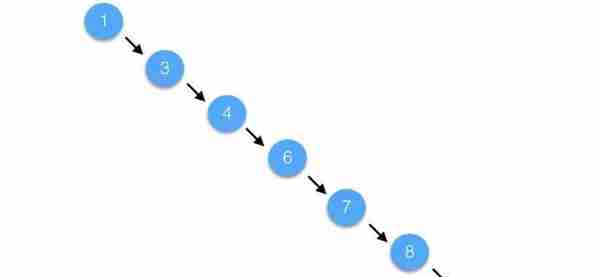
B+树是平衡树的一种,是不会退化成链表的,树的高度都是相对比较低的(基本符合矮矮胖胖(均衡)的结构)【这样一来我们检索的时间复杂度就是O(logn)】!从上一节的图我们也可以看见,建立索引实际上就是建立一颗B+树。
B+树删除和修改具体可参考:
1.4哈希索引
除了B+树之外,还有一种常见的是哈希索引。
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
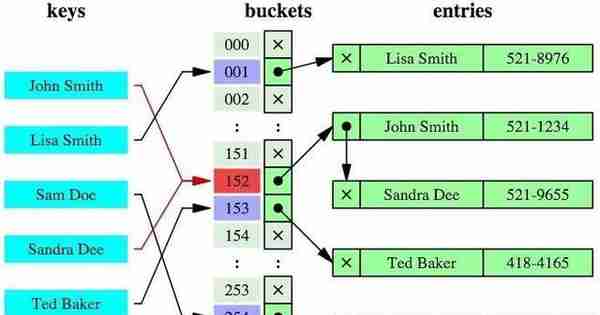
看起来哈希索引很牛逼啊,但其实哈希索引有好几个局限(根据他本质的原理可得):
参考资料:
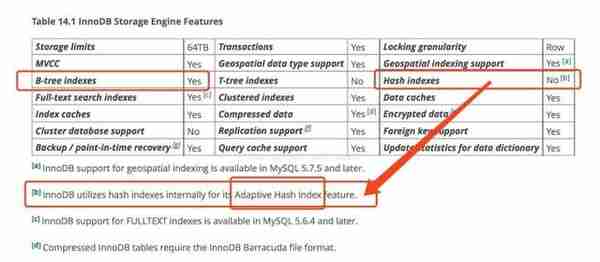
1.5InnoDB支持哈希索引吗?
主流的还是使用B+树索引比较多,对于哈希索引,InnoDB是自适应哈希索引的(hash索引的创建由InnoDB存储引擎引擎自动优化创建,我们干预不了)!
参考资料:
1.6聚集和非聚集索引
简单概括:
区别:
非聚集索引也叫做二级索引,不用纠结那么多名词,将其等价就行了~
非聚集索引在建立的时候也未必是单列的,可以多个列来创建索引。
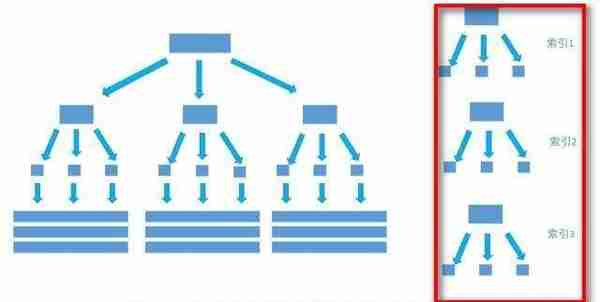
在创建多列索引中也涉及到了一种特殊的索引-->覆盖索引
比如说:
1.7索引最左匹配原则
最左匹配原则:
例子:
1.8=、in自动优化顺序
不需要考虑=、in等的顺序,mysql会自动优化这些条件的顺序,以匹配尽可能多的索引列。
例子:
1.9索引总结
索引在数据库中是一个非常重要的知识点!上面谈的其实就是索引最基本的东西,要创建出好的索引要顾及到很多的方面:
参考资料:
二、锁
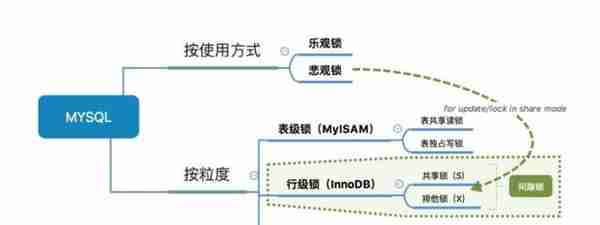
在mysql中的锁看起来是很复杂的,因为有一大堆的东西和名词:排它锁,共享锁,表锁,页锁,间隙锁,意向排它锁,意向共享锁,行锁,读锁,写锁,乐观锁,悲观锁,死锁。这些名词有的博客又直接写锁的英文的简写--->X锁,S锁,IS锁,IX锁,MMVC...
锁的相关知识又跟存储引擎,索引,事务的隔离级别都是关联的....
这就给初学数据库锁的人带来不少的麻烦~~~于是我下面就简单整理一下数据库锁的知识点,希望大家看完会有所帮助。
2.1为什么需要学习数据库锁知识
不少人在开发的时候,应该很少会注意到这些锁的问题,也很少会给程序加锁(除了库存这些对数量准确性要求极高的情况下)
一般也就听过常说的乐观锁和悲观锁,了解过基本的含义之后就没了~~~
定心丸:即使我们不会这些锁知识,我们的程序在一般情况下还是可以跑得好好的。因为这些锁数据库隐式帮我们加了
只会在某些特定的场景下才需要手动加锁,学习数据库锁知识就是为了:
2.2表锁简单介绍
首先,从锁的粒度,我们可以分成两大类:
不同的存储引擎支持的锁粒度是不一样的:
InnoDB只有通过索引条件检索数据才使用行级锁,否则,InnoDB将使用表锁
表锁下又分为两种模式:

从上面已经看到了:读锁和写锁是互斥的,读写操作是串行。
值得注意的是:
The LOCAL modifier enables nonconflicting INSERT statements (concurrent inserts) by other sessions to execute while the lock is held. (See Section 8.11.3, “Concurrent Inserts”.) However, READ LOCAL cannot be used if you are going to manipulate the database using processes external to the server while you hold the lock. For InnoDB tables, READ LOCAL is the same as READ
参考资料:
2.2行锁细讲
上边简单讲解了表锁的相关知识,我们使用Mysql一般是使用InnoDB存储引擎的。InnoDB和MyISAM有两个本质的区别:
从上面也说了:我们是很少手动加表锁的。表锁对我们程序员来说几乎是透明的,即使InnoDB不走索引,加的表锁也是自动的!
我们应该更加关注行锁的内容,因为InnoDB一大特性就是支持行锁!
InnoDB实现了以下两种类型的行锁。
看完上面的有没有发现,在一开始所说的:X锁,S锁,读锁,写锁,共享锁,排它锁其实总共就两个锁,只不过它们有多个名字罢了~~~
Intention locks do not block anything except full table requests (for example, LOCK TABLES ... WRITE). The main purpose of intention locks is to show that someone is locking a row, or going to lock a row in the table.
另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁:
参考资料:
2.2.1MVCC和事务的隔离级别
数据库事务有不同的隔离级别,不同的隔离级别对锁的使用是不同的,锁的应用最终导致不同事务的隔离级别
MVCC(Multi-Version Concurrency Control)多版本并发控制,可以简单地认为:MVCC就是行级锁的一个变种(升级版)。
在表锁中我们读写是阻塞的,基于提升并发性能的考虑,MVCC一般读写是不阻塞的(所以说MVCC很多情况下避免了加锁的操作)
快照有两个级别:
我们在初学的时候已经知道,事务的隔离级别有4种:
Serializable
Read uncommitted会出现的现象--->脏读:一个事务读取到另外一个事务未提交的数据
例子:A向B转账,A执行了转账语句,但A还没有提交事务,B读取数据,发现自己账户钱变多了!B跟A说,我已经收到钱了。A回滚事务【rollback】,等B再查看账户的钱时,发现钱并没有多。出现脏读的本质就是因为操作(修改)完该数据就立马释放掉锁,导致读的数据就变成了无用的或者是错误的数据。
Read committed避免脏读的做法其实很简单:
但Read committed出现的现象--->不可重复读:一个事务读取到另外一个事务已经提交的数据,也就是说一个事务可以看到其他事务所做的修改
注:A查询数据库得到数据,B去修改数据库的数据,导致A多次查询数据库的结果都不一样【危害:A每次查询的结果都是受B的影响的,那么A查询出来的信息就没有意思了】
上面也说了,Read committed是语句级别的快照!每次读取的都是当前最新的版本!
Repeatable read避免不可重复读是事务级别的快照!每次读取的都是当前事务的版本,即使被修改了,也只会读取当前事务版本的数据。
呃...如果还是不太清楚,我们来看看InnoDB的MVCC是怎么样的吧(摘抄《高性能MySQL》)


至于虚读(幻读):是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。
参考资料:
扩展阅读:
2.3乐观锁和悲观锁
无论是Read committed还是Repeatable read隔离级别,都是为了解决读写冲突的问题。
单纯在Repeatable read隔离级别下我们来考虑一个问题:
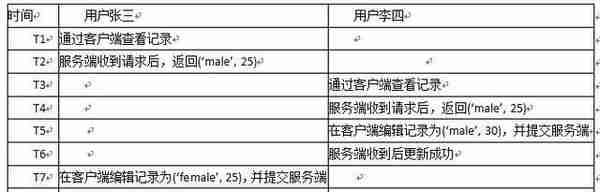
此时,用户李四的操作就丢失掉了:
(ps:暂时没有想到比较好的例子来说明更新丢失的问题,虽然上面的例子也是更新丢失,但一定程度上是可接受的..不知道有没有人能想到不可接受的更新丢失例子呢...)
解决的方法:
2.3.1悲观锁
所以,按照上面的例子。我们使用悲观锁的话其实很简单(手动加行锁就行了):
在select 语句后边加了 for update相当于加了排它锁(写锁),加了写锁以后,其他的事务就不能对它修改了!需要等待当前事务修改完之后才可以修改.
2.3.2乐观锁
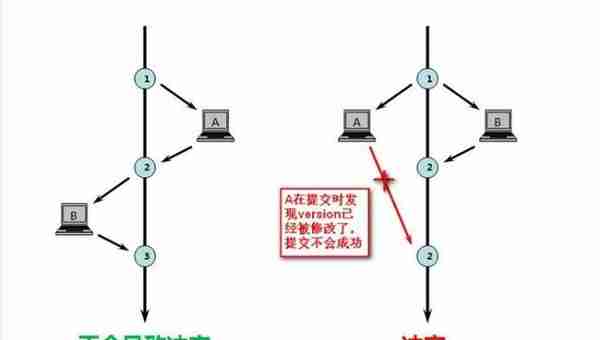
乐观锁不是数据库层面上的锁,是需要自己手动去加的锁。一般我们添加一个版本字段来实现:
具体过程是这样的:
张三select * from table --->会查询出记录出来,同时会有一个version字段

李四select * from table --->会查询出记录出来,同时会有一个version字段
李四对这条记录做修改:update A set Name=lisi,version=version+1 where ID=#{id} and version=#{version},判断之前查询到的version与现在的数据的version进行比较,同时会更新version字段
此时数据库记录如下:

张三也对这条记录修改:update A set Name=lisi,version=version+1 where ID=#{id} and version=#{version},但失败了!因为当前数据库中的版本跟查询出来的版本不一致!
参考资料:
2.4间隙锁GAP
当我们用范围条件检索数据而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合范围条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”。InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁。
值得注意的是:间隙锁只会在Repeatable read隔离级别下使用~
例子:假如emp表中只有101条记录,其empid的值分别是1,2,...,100,101
Select * from emp where empid > 100 for update;
上面是一个范围查询,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的“间隙”加锁。
InnoDB使用间隙锁的目的有两个:
2.5死锁
并发的问题就少不了死锁,在MySQL中同样会存在死锁的问题。
但一般来说MySQL通过回滚帮我们解决了不少死锁的问题了,但死锁是无法完全避免的,可以通过以下的经验参考,来尽可能少遇到死锁:
参考资料:
2.6锁总结
上面说了一大堆关于MySQL数据库锁的东西,现在来简单总结一下。
表锁其实我们程序员是很少关心它的:
现在我们大多数使用MySQL都是使用InnoDB,InnoDB支持行锁:
在默认的情况下,select是不加任何行锁的~事务可以通过以下语句显示给记录集加共享锁或排他锁。
InnoDB基于行锁还实现了MVCC多版本并发控制,MVCC在隔离级别下的Read committed和Repeatable read下工作。MVCC能够实现读写不阻塞!
InnoDB实现的Repeatable read隔离级别配合GAP间隙锁已经避免了幻读!
参考资料:
三、总结
本文主要介绍了数据库中的两个比较重要的知识点:索引和锁。他俩可以说息息相关的,锁会涉及到很多关于索引的知识~
